
Suite à notre atelier en ligne, vous allez (re)découvrir un cas d’usage concret de Jira Software Cloud et Bitbucket Cloud pour la gestion et le développement d’un projet d’une application IT avec cet article. En reliant Jira Software Cloud et Bitbucket Cloud vous allez découvrir la puissance de la combinaison des deux outils dans l’Intégration Continue (build) et le Déploiement Continu (deploy) pour gérer, suivre, tester et optimiser vos projets et développements informatiques.
Avec cet article, vous allez apprendre comment simplement :
- configurer et utiliser Jira Software Cloud pour gérer et suivre le déroulement d’un projet IT par un exemple d’usage concret,
- lier vos tickets dans Jira Software Cloud et votre code source dans Bitbucket Cloud pour facilement suivre vos développements informatiques,
- exécuter un contrôle de la qualité du code produit au moment build de votre projet IT avec Bitbucket Pipelines,
- exécuter des tests unitaires au moment build de votre projet IT avec Bitbucket Pipelines.
- déployer vos binaires issues du build avec une configuration dans Bitbucket Pipelines.
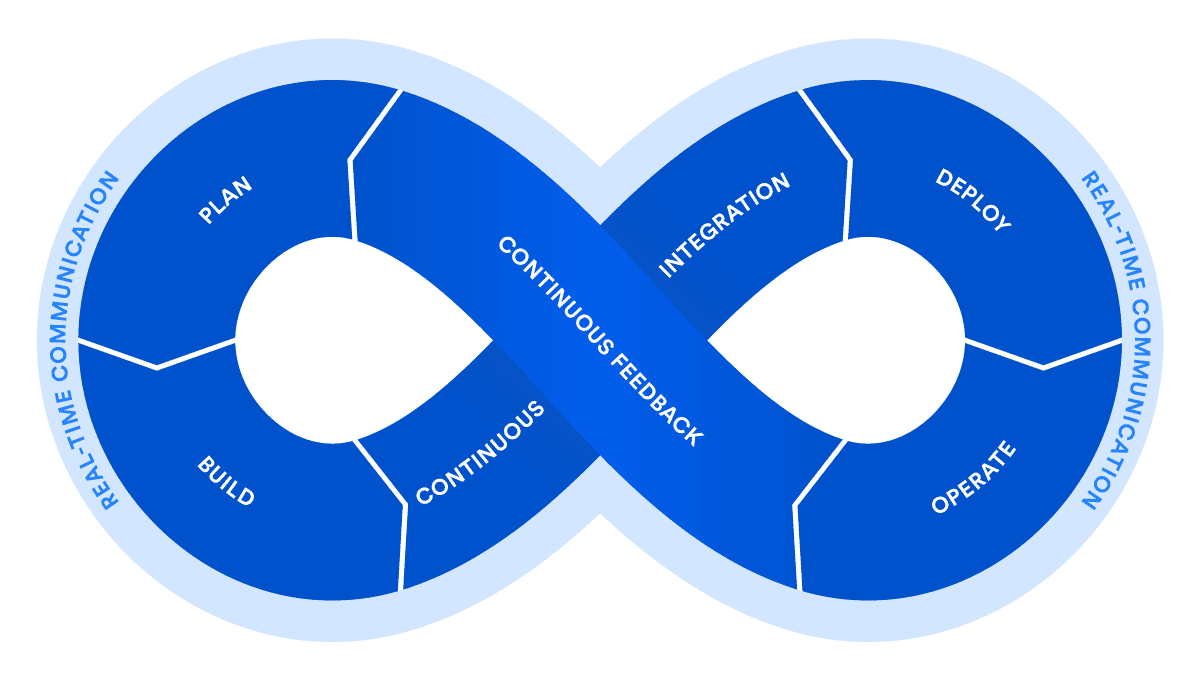 CI/CD : Définition et Concepts clés
CI/CD : Définition et Concepts clés
CI = Continuous Integration / CD = Continuous Deployment
CI : Intégration continue
Définition de l’Intégration Continue (Continuous Integration) : ensemble de pratiques utilisées en génie logiciel consistant à vérifier à chaque modification de code source que le résultat des modifications ne produit pas de régression dans l’application développée. Elle repose souvent sur la mise en place d’une brique logicielle permettant l’automatisation de tâches : compilation, tests unitaires et fonctionnels, validation produit, tests de performances… À chaque changement du code, cette brique logicielle va exécuter un ensemble de tâches et produire un ensemble de résultats, que le développeur peut par la suite consulter
Les éléments clés de l’Intégration Continue :
- Intégration continue = compiler le projet dès qu’une modification est apportée
- Intégrer systématiquement les changements de code dans la branche principale d’un dépôt
- Tester les changements le plus rapidement et le plus souvent possible
- Intégrer le code produit quotidiennement, voire plusieurs fois par jour
- Renforcer l’agilité
- Créer de l’engagement fort de la part d’une équipe
Les avantages de l’Intégration Continue :
- Accélérer le feedback sur les changements de code
- Renforcer la qualité du code produit
- Améliorer la productivité d’une équipe
- Faciliter l’automatisation des tests
- Obtenir des indicateurs de suivi fiables
CD : Déploiement continu
Définition du Déploiement Continu (Continuous Deployment) : approche d’ingénierie logicielle dans laquelle les fonctionnalités logicielles sont livrées fréquemment par le biais de déploiements automatisés. Elle nécessite aucune évaluation ni vérification manuelle des changements de code dans l’environnement de test, puisque les tests automatisés sont intégrés très tôt dans le processus de développement et se poursuivent tout au long des phases du lancement. On parle de livraison continue lorsque les développeurs livrent souvent et de manière régulière du nouveau code à tester aux équipes de l’assurance qualité (QA) et de l’exploitation.
Les éléments clés du Déploiement Continu :
- Automatiser les étapes de livraison, tout environnement confondus (dev, integration, production)
- Déploiement automatisé robuste et fiable
- Nécessite l’Intégration continue pour automatiser la production des livrables (build)
- Pousse la pratique DevOps à son extrême logique
- Offrir de nouvelles fonctionnalités à vos utilisateurs finaux et testeurs internes
Les avantages du Déploiement Continu :
- Donner de la visibilité sur ce qui est développé
- Permettre des tests d’interface sur les développements en cours
- Accélérer les feedbacks et la remonter de bugs
- Soulager l’équipe en charge des livraisons
- Automatiser les livraisons (même en Production !)
- Augmentation de la qualité des logiciels
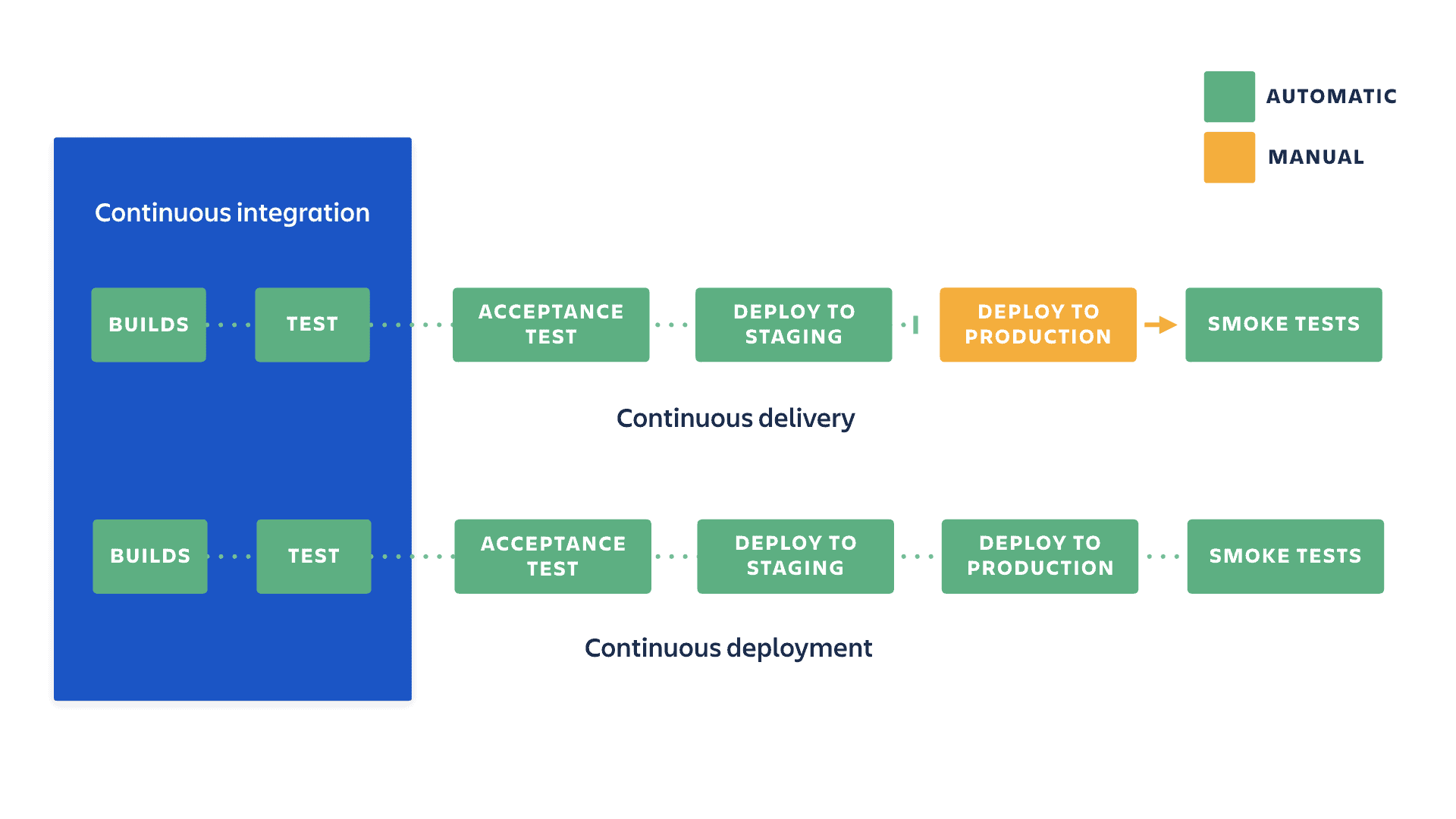
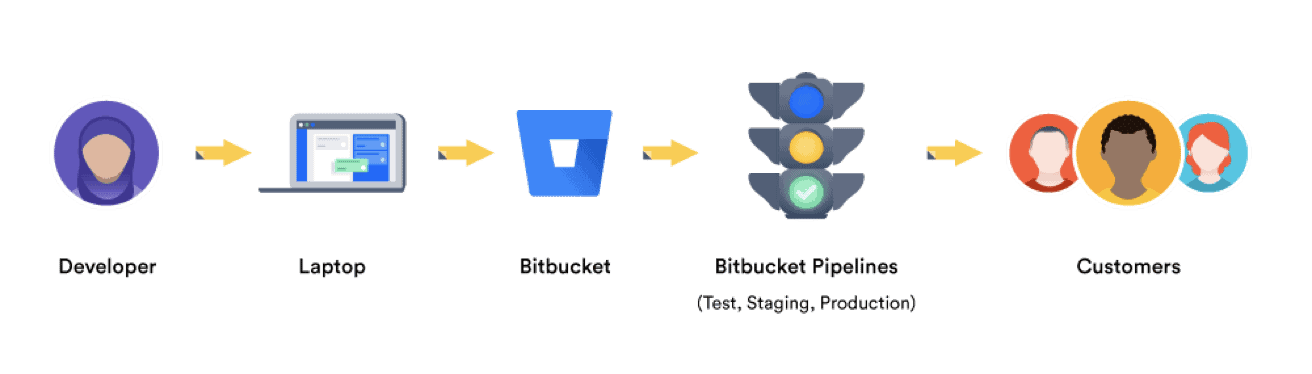
Le contexte de cette démonstration
Le projet IT est un projet simple comprenant 2 classes JAVA : HelloWorld.java et Calculation.java. On se focalise ici sur la configuration des outils et pas le code projet en lui-même. Les deux produits Atlassian Cloud utilisés :
- Jira Software Cloud : projet Jira Cloud = WORKSHOP-CI-CD
- Bitbucket Cloud : répertoire de code Bitbucket Cloud = demo-workshop-ci-cd-java
Les implémentations Jira Software Cloud :
- Un projet simple de gestion des tâches
- Un tableau de suivi des tâches Kanban avec un statut personnalisé
- Un changement de statut automatique au commit de code : De l’état TO DO vers IN PROGRESS
- Lien avec Bitbucket Cloud pour suivre les builds et les deployments directement dans Jira Software Cloud
Les implémentations Bitbucket Cloud :
- Répertoire de code source GIT
- Bitbucket Pipelines pour construire le binaire JAVA avec MAVEN
- Bitbucket Pipelines pour exécuter les tests unitaires avec JUNIT
- Bitbucket Pipelines pour contrôler le code avec CHECKSTYLE
- Bitbucket Pipelines pour déployer le binaire JAVA dans un gestionnaire de dépôt de binaires avec JFROG
- Un déploiement automatique pour Test
- Un déploiement manuel pour la Production (sans tag)
- Lien avec Jira Software Cloud

Construire la partition…
Première étape : commençons par Jira Software Cloud
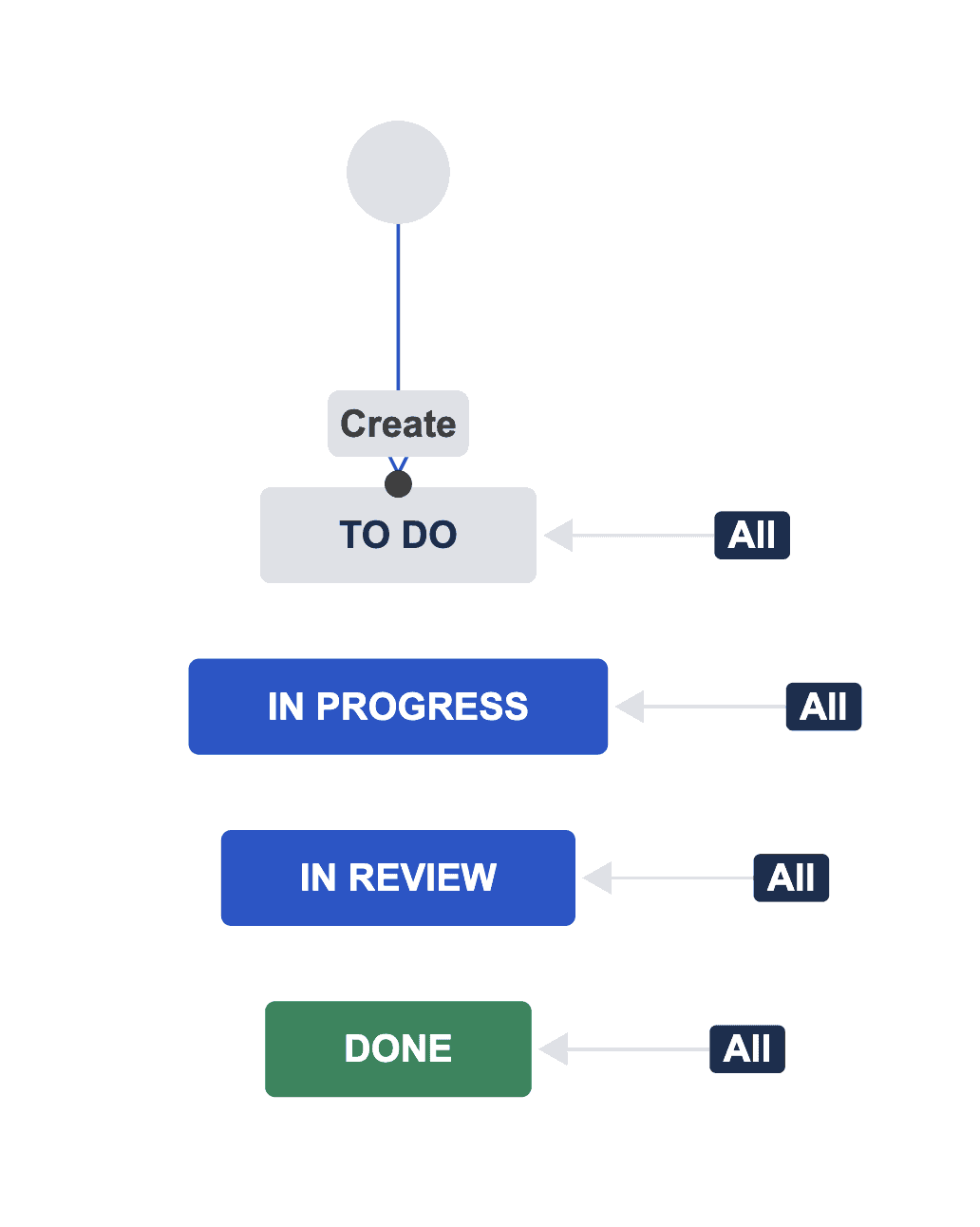
Le workflow du projet
Rien de spécial ici, on a simplement ajouté un état « In Review » au workflow de base fournit par Jira Software Cloud à la création d’un projet de type Kanban.
En savoir plus sur les workflows.
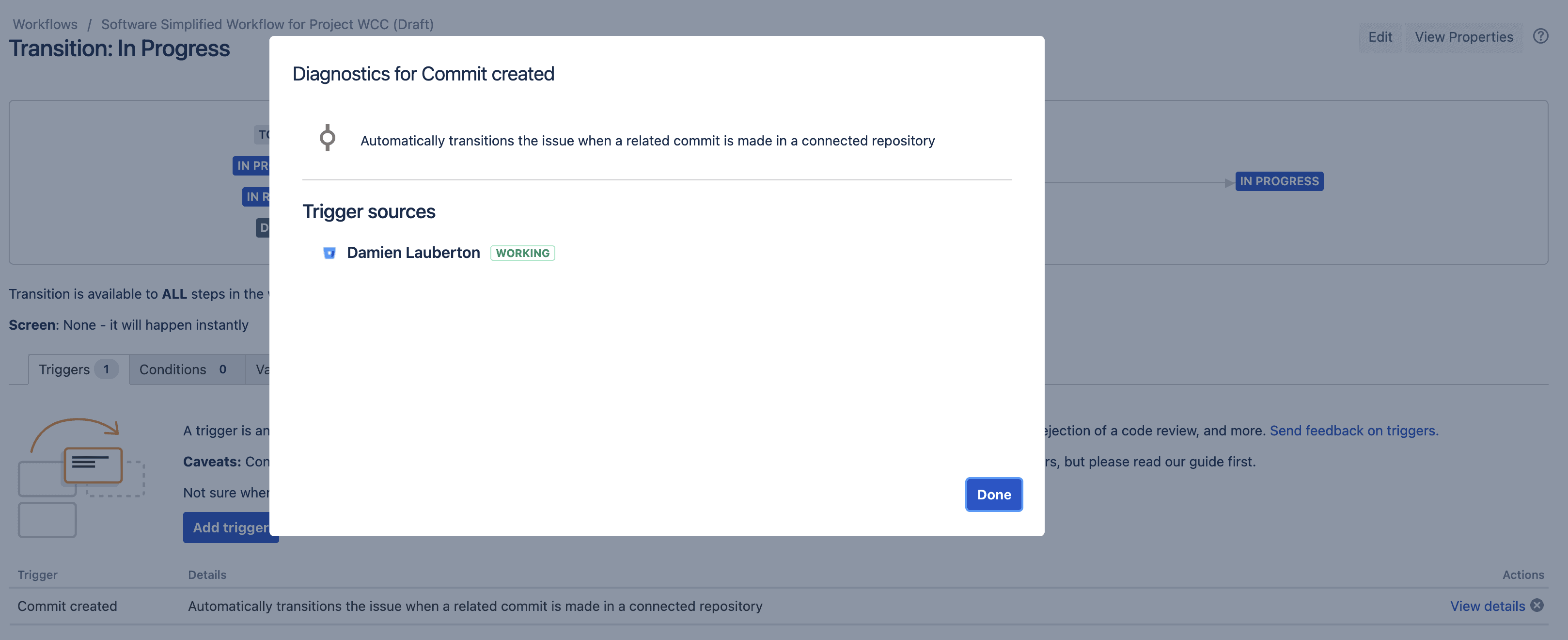
Le trigger magique
On a ajouté un trigger sur la transition globale « In Progress » : au commit de code sur Bitbucket, la demande chargera d’état pour aller sur « In Progress », très pratique. À vous d’imaginer les possibilités sur votre workflow personnalisé !
En savoir plus sur les triggers.
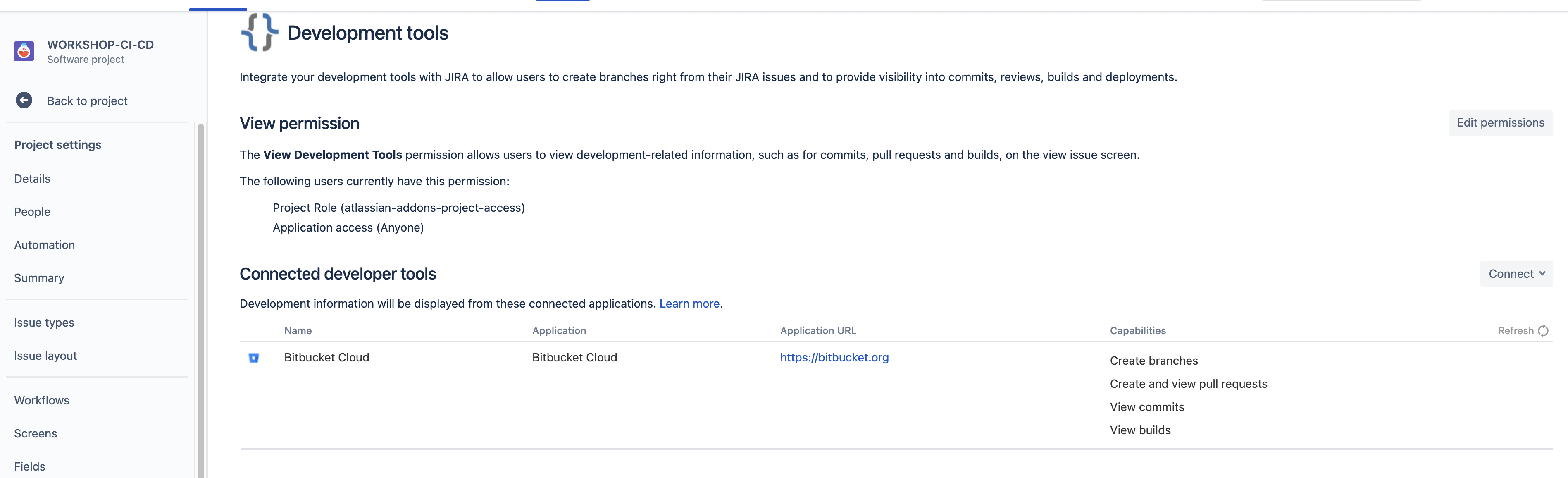
Le lien Jira Cloud <> Bitbucket Cloud
En reliant les deux outils, la puissance est entre vos mains. Depuis Jira Software Cloud vous aller pouvoir constater des éléments dans Bitbucket Cloud et inversement. L’intégration est extrêmement forte et intuitive, vous allez être surpris !
En savoir plus sur le lien Jira Cloud <> Bitbucket Cloud.
Seconde étape : Bitbucket Cloud
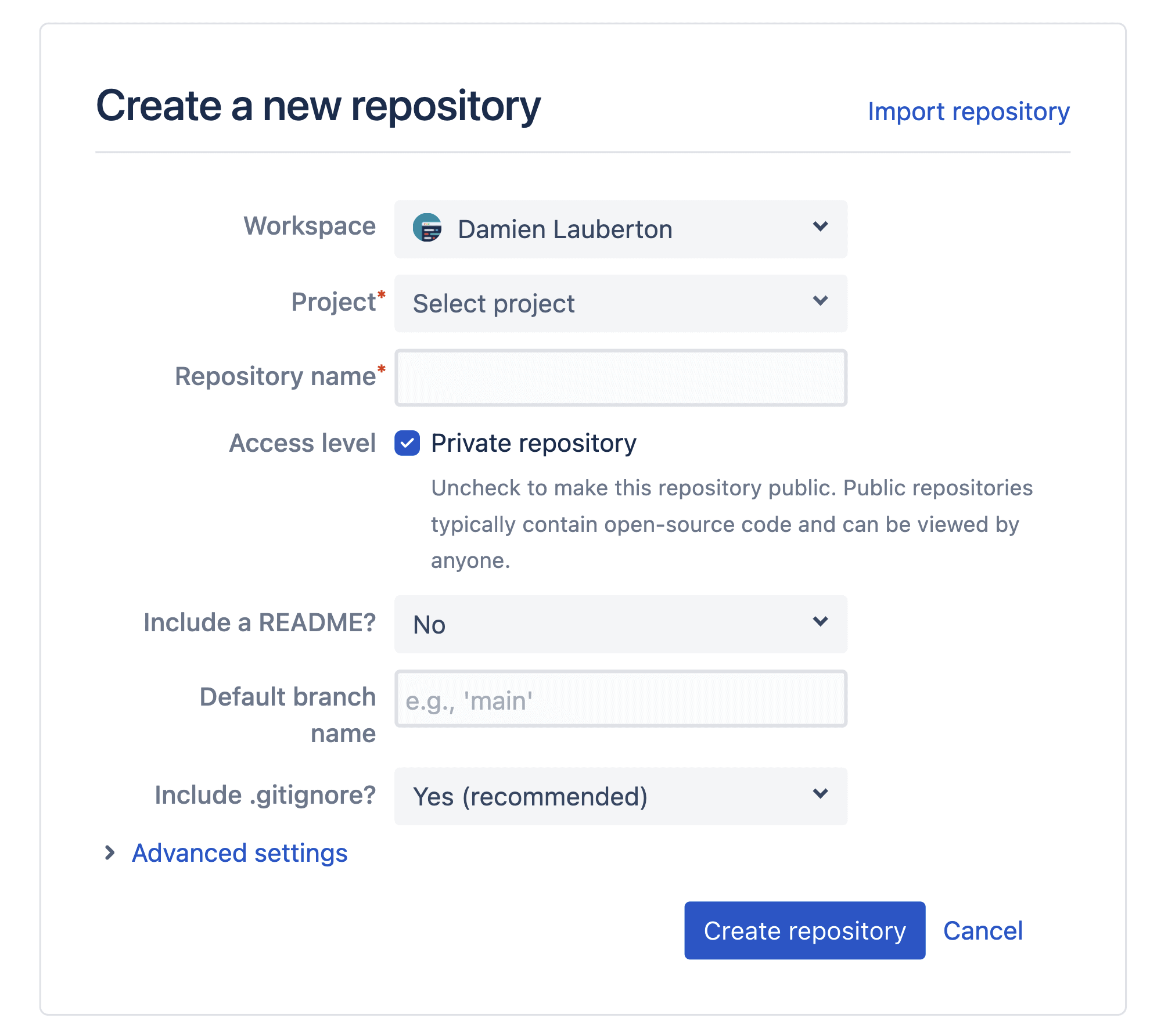
La création d’un répertoire de code source sur Bitbucket Cloud est la première étape, il permettra de stocker notre code source Java.
Créer un répertoire de code (dépôt) vide
- Cliquez sur + dans la barre latérale globale sur la gauche, puis, sous Create new (Créer), sélectionnez Repository (Dépôt).
- Donnez un nom au dépôt. C’est important ! Le nom d’un dépôt sera inclus dans son URL.
- Définissez l’option Include a README? (Inclure un fichier README ?) sur Yes, with a template (Oui, avec un modèle).
- Vous pouvez conserver les autres valeurs par défaut et cliquer sur Create (Créer)
En savoir plus sur la création d’un répertoire de code source sur Bitbucket Cloud.
La structure de notre projet Java dans Bitbucket Cloud et dans un terminal de commande
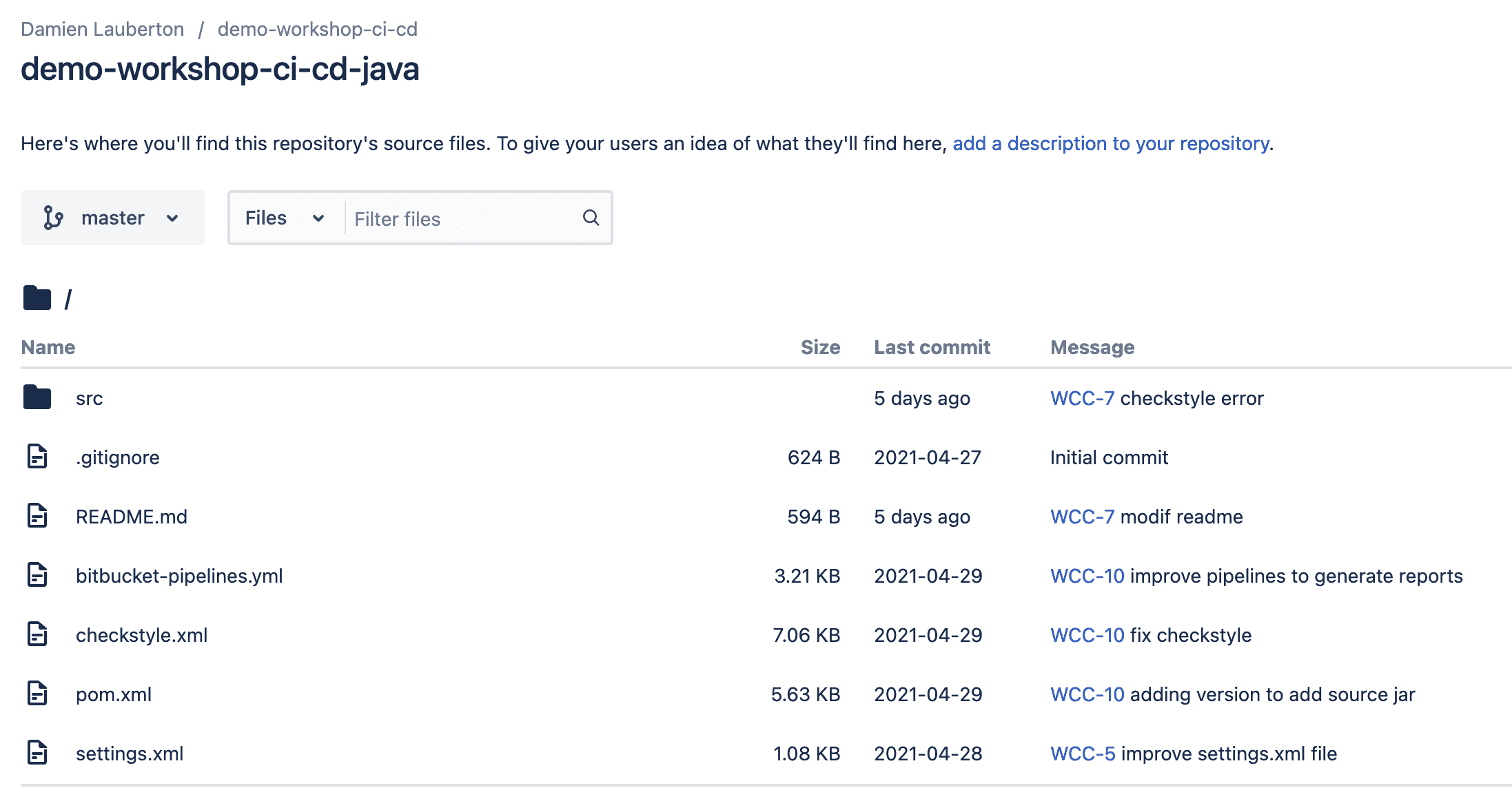
├── README.md ├── bitbucket-pipelines.yml ├── checkstyle.xml ├── pom.xml ├── settings.xml ├── src │ ├── main │ │ └── java │ │ └── com │ │ └── idalko │ │ ├── calculation │ │ │ ├── Calculation.java │ │ │ └── package-info.java │ │ ├── hello │ │ │ ├── HelloWorld.java │ │ │ └── package-info.java │ │ └── tests │ └── test │ └── java │ └── com │ └── idalko │ └── calculation │ └── tests │ ├── TestCalculation.java │ └── package-info.java
La consigne impérative à chaque commit de code pour que Jira Software Cloud et Bitbucket Cloud fonctionne ensemble :
le message de votre commit doit impérativement contenir le numéro unique du ticket Jira concerné
Un exemple de commit git avec un message et un numéro unique de ticket Jira :
git commit -m "WCC-7 un exemple de commit git avec un message et un numéro unique de ticket Jira" ./README.md
Troisième étape : Bitbucket Pipelines
Après avoir activer Pipelines sur votre dépôt de sources, il est temps de le configurer pour nos besoins grâce au fichier bitbucket-pipelines.yml :
- une configuration principale pour la branche « master »
- une configuration secondaire pour les branches de fonctionnalités « feature/* »
- une configuration de déploiement pour un environnement de Test
- une configuration de déploiement pour un environnement de Production
On part d’une image docker nous permettant d’avoir un environnement ou construire notre binaire java, ici on utilise une image offerte par Maven mais vous pouvez utiliser votre propre image Docker avec tous vos outils pré-installés et publiée cette image sur le Hub Docker – https://hub.docker.com pour permettre à Bitbucket Pipelines d’y accéder en public ou en privé : (on reviendra plus tard à la configuration Maven de notre projet Java) :
image: maven:3.6.3
Puis on configure la branche « master » pour l’Intégration continue (build) et le Déploiement continu (deploy) :
branches:
master:
- parallel:
- step:
name: Build and Test
caches:
- maven
script:
- mvn verify --file pom.xml -s settings.xml
after-script:
# Collect checkstyle check results if any and convert to Bitbucket Code Insights.
- pipe: atlassian/checkstyle-report:0.2.0
- step:
name: Security Scan
script:
# Run a security scan for sensitive data.
# See more security tools at https://bitbucket.org/product/features/pipelines/integrations?&category=security
- pipe: atlassian/git-secrets-scan:0.4.3
- step:
name: Deploy to Test
deployment: Test
script:
- mvn clean deploy -s settings.xml
- step:
name: Deploy to Production
deployment: Production
trigger: manual
script:
- mvn --batch-mode release:update-versions -DreleaseVersion=1.0
- mvn clean deployQuelques explications :
- Sur l’étape (step) « Build and Test » , on met en cache maven (répertoire ~/.m2/repository),
- Puis on lance la construction de notre binaire java avec nos fichiers de configuration en entrée (mvn verify),
- Ensuite on exécute une Bitbucket Pipe pour contrôler notre code avec Checkstyle (pour Java) et obtenir un rapport,
- L’étape (step) « Security Scan sera exécutée en parallèle de l’étape « Build and Test », c’est un test proposé par Atlassian pour vérifier que votre projet n’utilise pas de données sensibles « en clair » comme les mots de passe par exemple,
- Sur l’étape (step) « Deploy to Test » on déploie notre binaire sur une plateforme de dépôt de binaire comme JFrog utilisé au sein d’iDalko par exemple,
- Et enfin sur l’étape (step) « Deploy to Production », on incrémente la version de notre projet (rapide ici on devrait tagger notre projet), noté que le déclenchement sera manuel ici avec la commande trigger: manual
Pour en savoir plus sur les Bitbucket Pipes : Grâce aux Bitbucket Pipes vous allez pouvoir créez des workflows puissants et automatisés d’intégration continue et de déploiement continu de manière plug and play. Vous pouvez utiliser des Pipes pré-configurées ou créez et partagez vos propres Pipes.
Enfin, de la même manière, on configure la branche « feature/* » pour l’Intégration continue (build) et le Déploiement continu (deploy) :
feature/*:
- parallel:
- step:
name: Build and Test
caches:
- maven
script:
- mvn versions:set --file pom.xml -DnewVersion=1.0-FEATURE-SNAPSHOT
- mvn verify -s settings.xml
after-script:
# Collect checkstyle check results if any and convert to Bitbucket Code Insights.
- pipe: atlassian/checkstyle-report:0.2.0
- step:
name: Security Scan
script:
# Run a security scan for sensitive data.
# See more security tools at https://bitbucket.org/product/features/pipelines/integrations?&category=security
- pipe: atlassian/git-secrets-scan:0.4.3
- step:
name: Deploy to Test
deployment: Test
script:
- mvn versions:set --file pom.xml -DnewVersion=1.0-FEATURE-SNAPSHOT
- mvn clean deploy -s settings.xml
- step:
name: Deploy to Production
deployment: Production
trigger: manual
script:
- mvn --batch-mode release:update-versions -DreleaseVersion=1.0
- mvn clean deployQuelques explications :
- Sur l’étape (step) « Build and Test » , on met en cache maven (répertoire ~/.m2/repository),
- On force la version de notre configuration maven pour déposer nos binaires un dossier à part sur notre plateforme de dépôts de binaire (mvn versions:set)
- Puis on lance la construction de notre binaire java avec nos fichiers de configuration en entrée (mvn verify),
- Ensuite on exécute une Bitbucket Pipe pour contrôler notre code avec Checkstyle (pour Java) et obtenir un rapport,
- L’étape (step) « Security Scan sera exécutée en parallèle de l’étape « Build and Test », c’est un test proposé par Atlassian pour vérifier que votre projet n’utilise pas de données sensibles « en clair » comme les mots de passe par exemple,
- Sur l’étape (step) « Deploy to Test » on déploie notre binaire sur une plateforme de dépôt de binaire comme JFrog utilisé au sein d’iDalko par exemple,
- Et enfin sur l’étape (step) « Deploy to Production », on incrémente la version de notre projet (rapide ici on devrait tagger notre projet), noté que le déclenchement sera manuel ici avec la commande trigger: manual
Quatrième étape : Maven dans le projet JAVA
Petit rappel sur Maven : Apache Maven (couramment appelé Maven) est un outil de gestion et d’automatisation de production des projets logiciels Java en général et Java EE en particulier. Il est utilisé pour automatiser l’intégration continue lors d’un développement de logiciel. Maven est géré par l’organisation Apache Software Foundation.
Pour décrire les dépendances de notre projet Java, on va donc construire un fichier nommé pom.xml :
- le groupid : le package utilisé
- l’artifactid : le nom de notre binaire Java (jar)
- la version initiale de notre projet Java et de notre binaire
- le packaging, ici en jar
- et enfin les propriétés maven qui indique la version de Java a utilisé pour compiler notre projet ici Java 7
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<groupId>com.idalko.hello</groupId>
<artifactId>my-hello-idalko</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<modelVersion>4.0.0</modelVersion>
<name>iDalkoHello</name>
<properties>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
</properties>Notre première dépendance : Junit pour l’exécution des tests unitaires sur notre projet Java, noté que le scope ici est important. On souhaite utiliser cette dépendance pour nos tests seulement le scope est très important ici car on ne souhaite pas embarquer le jar Junit dans notre binaire projet.
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.1</version>
<scope>test</scope>
</dependency>
</dependencies>Et les dépendances pour produire un rapport de test unitaire :
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-report-plugin</artifactId>
<version>3.0.0-M5</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-failsafe-plugin</artifactId>
<version>3.0.0-M5</version>
<executions>
<execution>
<goals>
<goal>integration-test</goal>
<goal>verify</goal>
</goals>
</execution>
</executions>
</plugin>La configuration pour pouvoir utiliser Checkstyle et contrôler la qualité de notre code :
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-checkstyle-plugin</artifactId>
<version>3.1.2</version>
<dependencies>
<dependency>
<groupId>com.puppycrawl.tools</groupId>
<artifactId>checkstyle</artifactId>
<version>8.38</version>
</dependency>
</dependencies>
<configuration>
<configLocation>checkstyle.xml</configLocation>
<includeTestSourceDirectory>true</includeTestSourceDirectory>
<encoding>UTF-8</encoding>
<consoleOutput>true</consoleOutput>
<failsOnError>true</failsOnError>
<linkXRef>false</linkXRef>
</configuration>
<executions>
<execution>
<id>validate</id>
<phase>validate</phase>
<goals>
<goal>check</goal>
</goals>
</execution>
</executions>
</plugin>Et enfin la plateforme de déploiement pour déployer nos binaires et les rendre disponible pour un déploiement par une autre équipe, on utilise ici Jfrog :
<distributionManagement>
<repository>
<uniqueVersion>false</uniqueVersion>
<id>plugins-release-local</id>
<name>Idalko Release Repository</name>
<url>http://${USERBUILDER}:${PASSBUILDER}@artifactory.idalko.com/artifactory/plugins-release-local</url>
<layout>default</layout>
</repository>
<snapshotRepository>
<uniqueVersion>true</uniqueVersion>
<id>plugins-snapshot-local</id>
<name>Idalko Snapshot Repository</name>
<url>http://${USERBUILDER}:${PASSBUILDER}@artifactory.idalko.com/artifactory/plugins-snapshot-local</url>
<layout>default</layout>
</snapshotRepository>
</distributionManagement>
</project>${USERBUILDER} et ${PASSBUILDER} sont des variables d’environnement Bitbucket pour ne pas utiliser ces informations en clair dans nos configurations. En savoir plus sur les variables d’environnement Bitbucket.
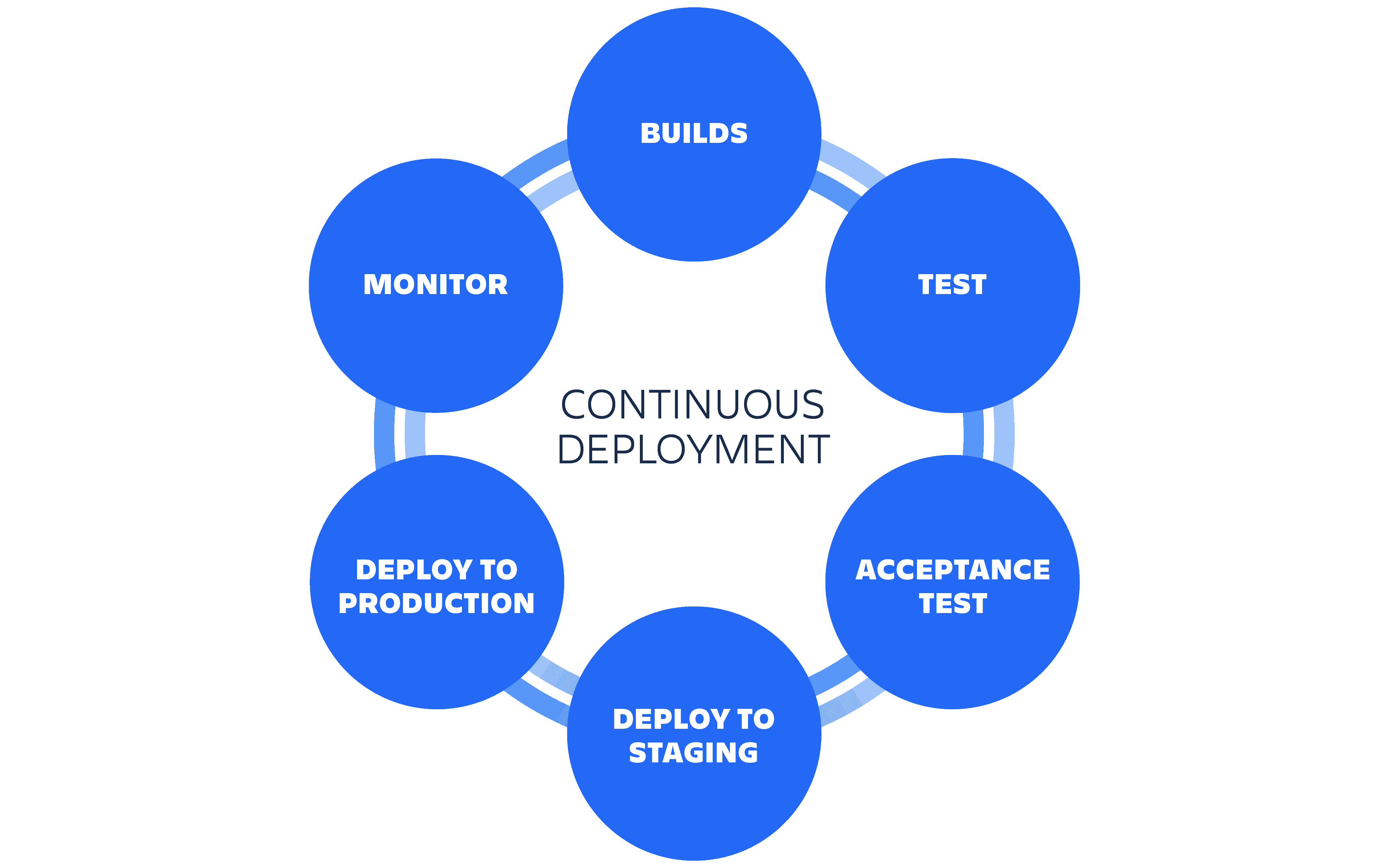
Un résumé de l’enchainement des différentes plateformes et de la partition qui va être jouée :
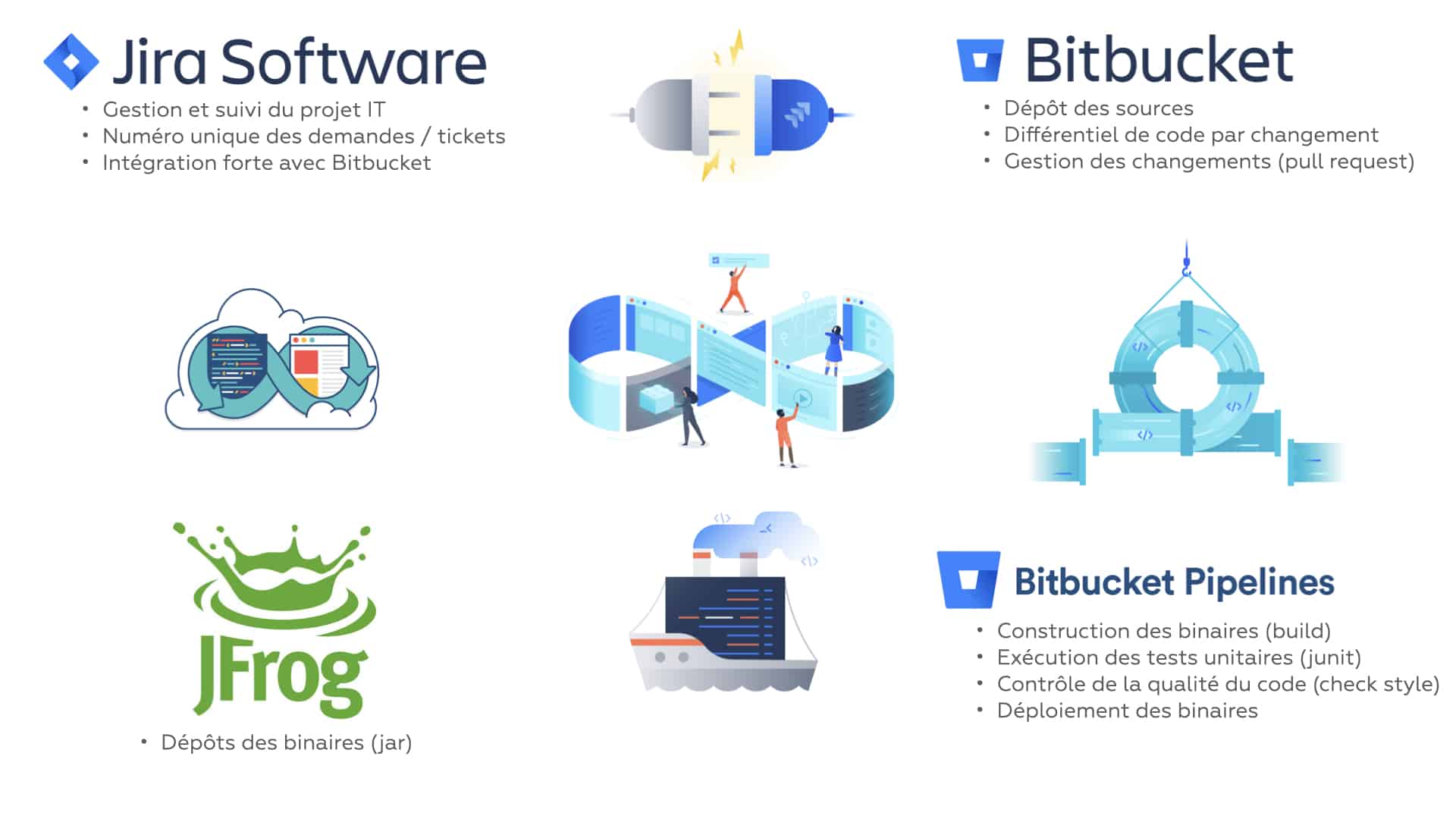
En avant la musique…
Après avoir écrit la partition, on peut désormais jouer notre morceau de musique. Ce qui va se passer lors d’un commit de code avec un message contenant le numéro unique du ticket Jira concerné :
- le ticket Jira associé va transitionner sur l’état « In Progress »
- un build sera déclenché sur Bitbucket avec Pipelines
- les tests unitaires du projet seront exécuté et un rapport sera produit
- la qualité du code sera controlée et un rapport sera produit
- Si le binaire est construit et que le build est « vert »
- le déploiement du binaire se fera automatiquement sur notre dépôt de binaire en environnement (répertoire) de Test
- on pourra ensuite décider de pousser ce binaire dans notre dépôt sur l’environnement (répertoire) de Production manuellement
Un aperçu des différents résultats de build dans Bitbucket
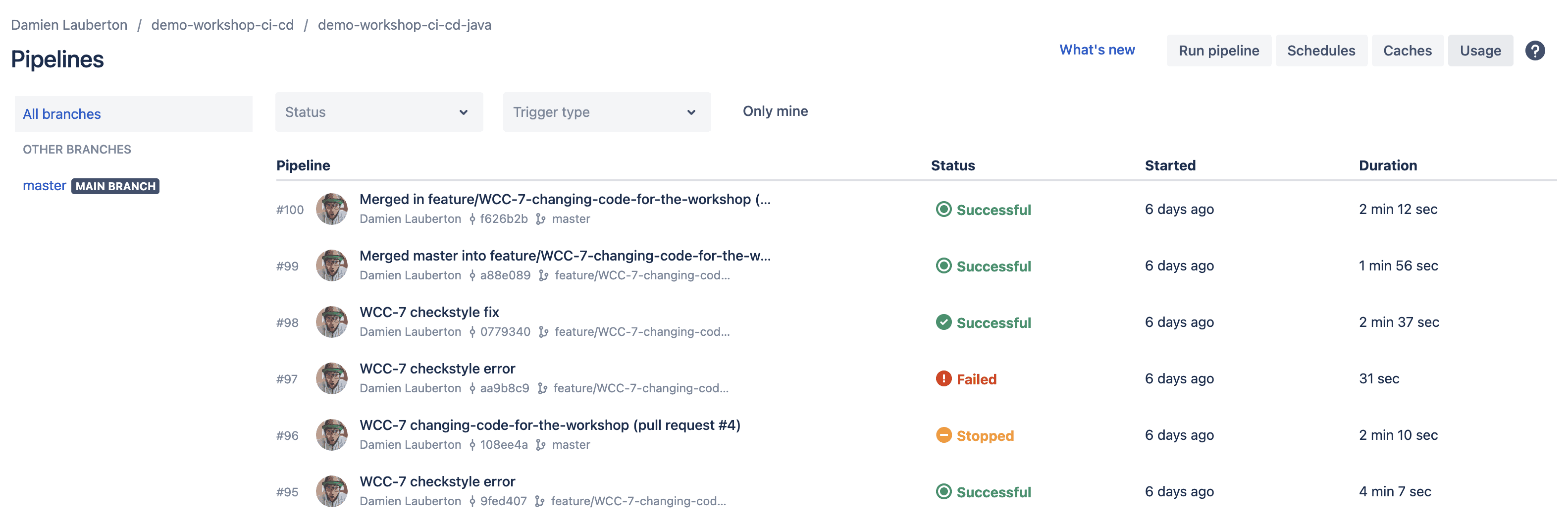
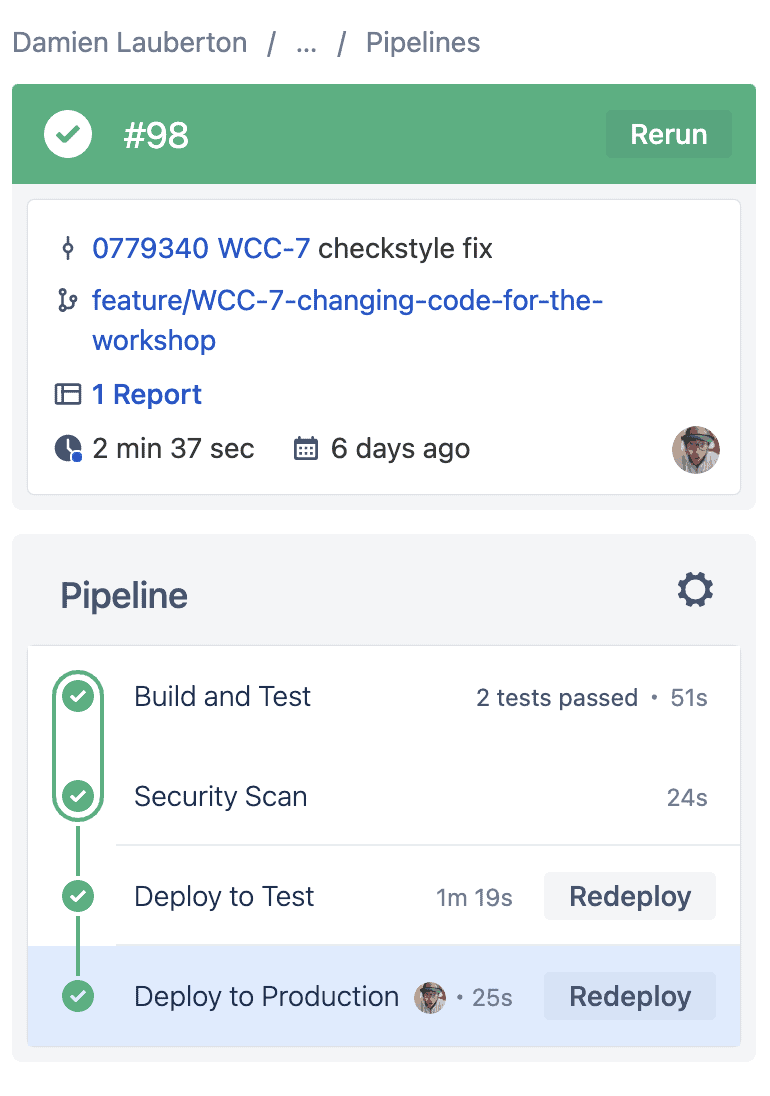
Un build réussit
- Il est possible de rejouer les différents déploiements manuellement
- On retrouve des informations utiles : durée du build, branches associées, commit associé, etc.
- La couleur parle à tout le monde, vert = succès
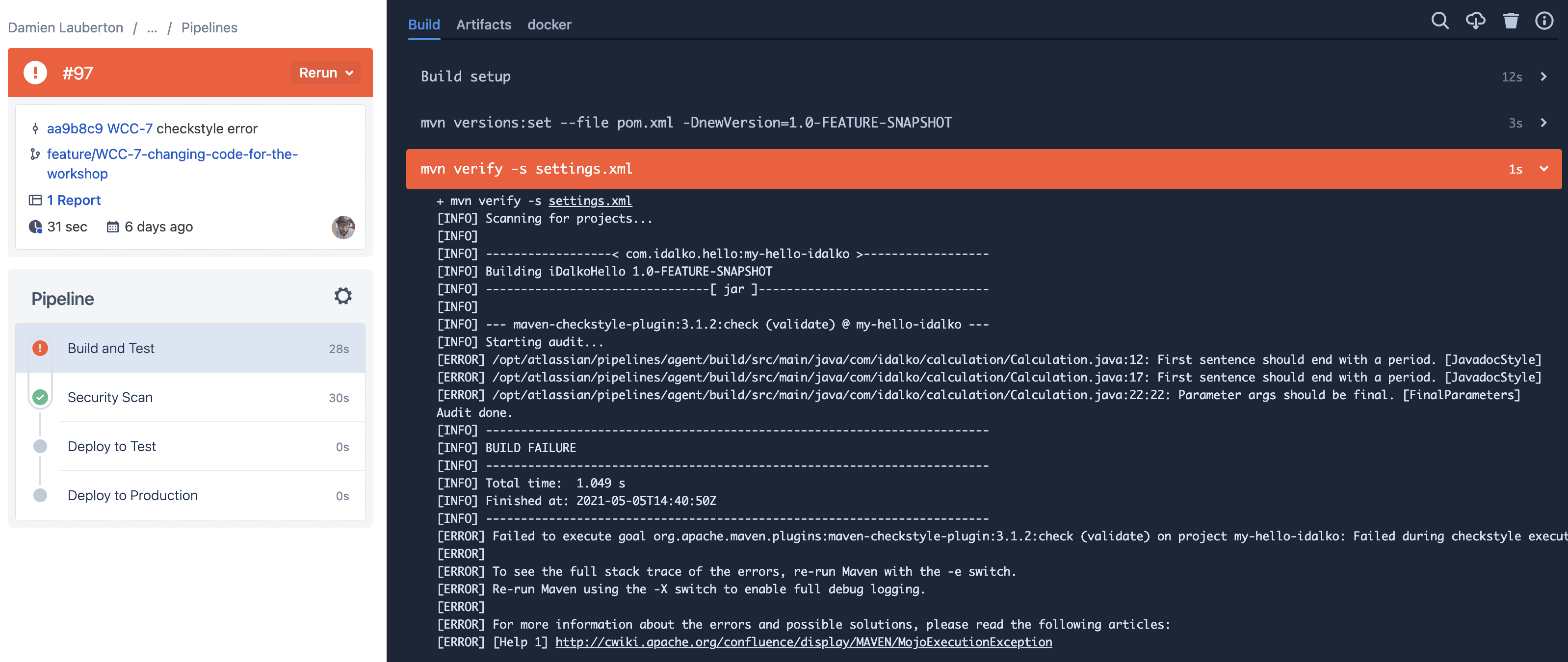
Un build échoué
- Il est possible de relancer le build manuellement
- On retrouve des informations utiles : durée du build, branches associées, commit associé, rapport, etc.
- Le détail de l’erreur au build, mais pas très lisible ici
- La couleur parle à tout le monde, rouge = échec
Le rapport Checkstyle sera beaucoup plus lisible :

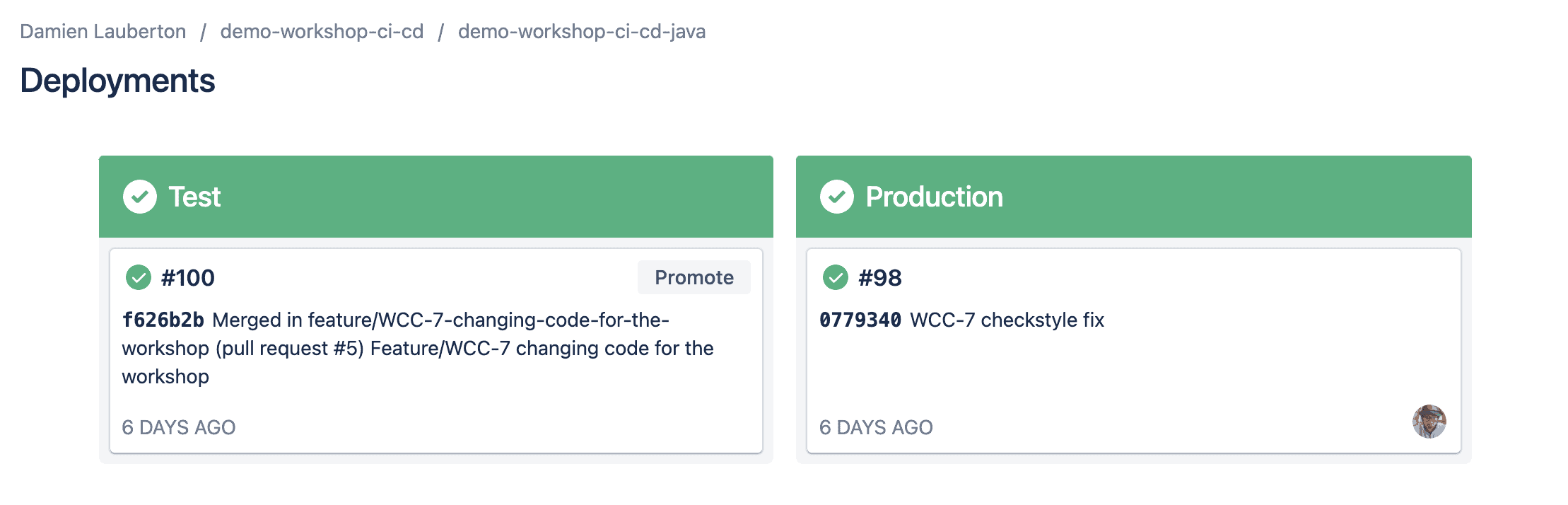
La vue des déploiements vers JFrog
Ce qui est très pratique ici : on peut directement promouvoir (promote) un build depuis l’environnement de test vers l’environnement de Production en 1 seul clic grâce au bouton Promote !
L’environnement de Test
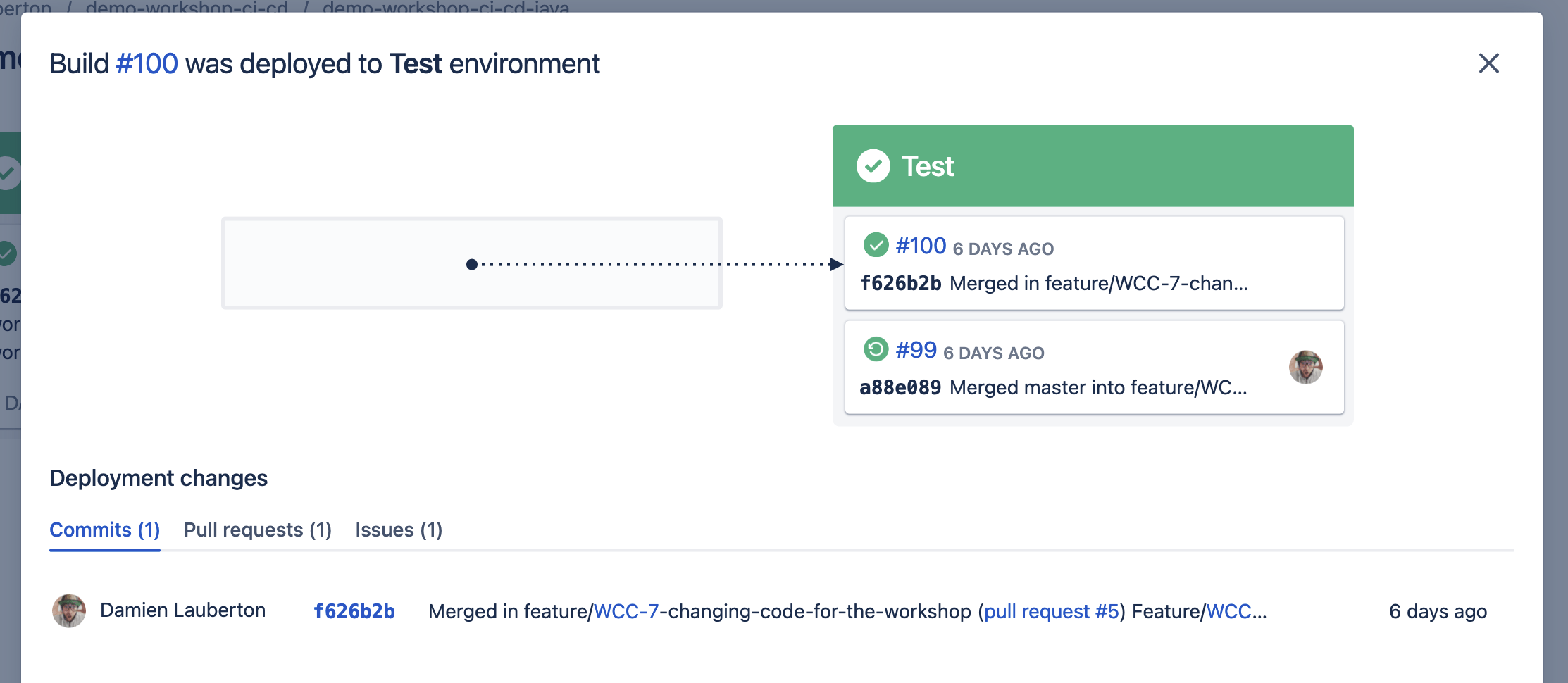
L’environnement de Production
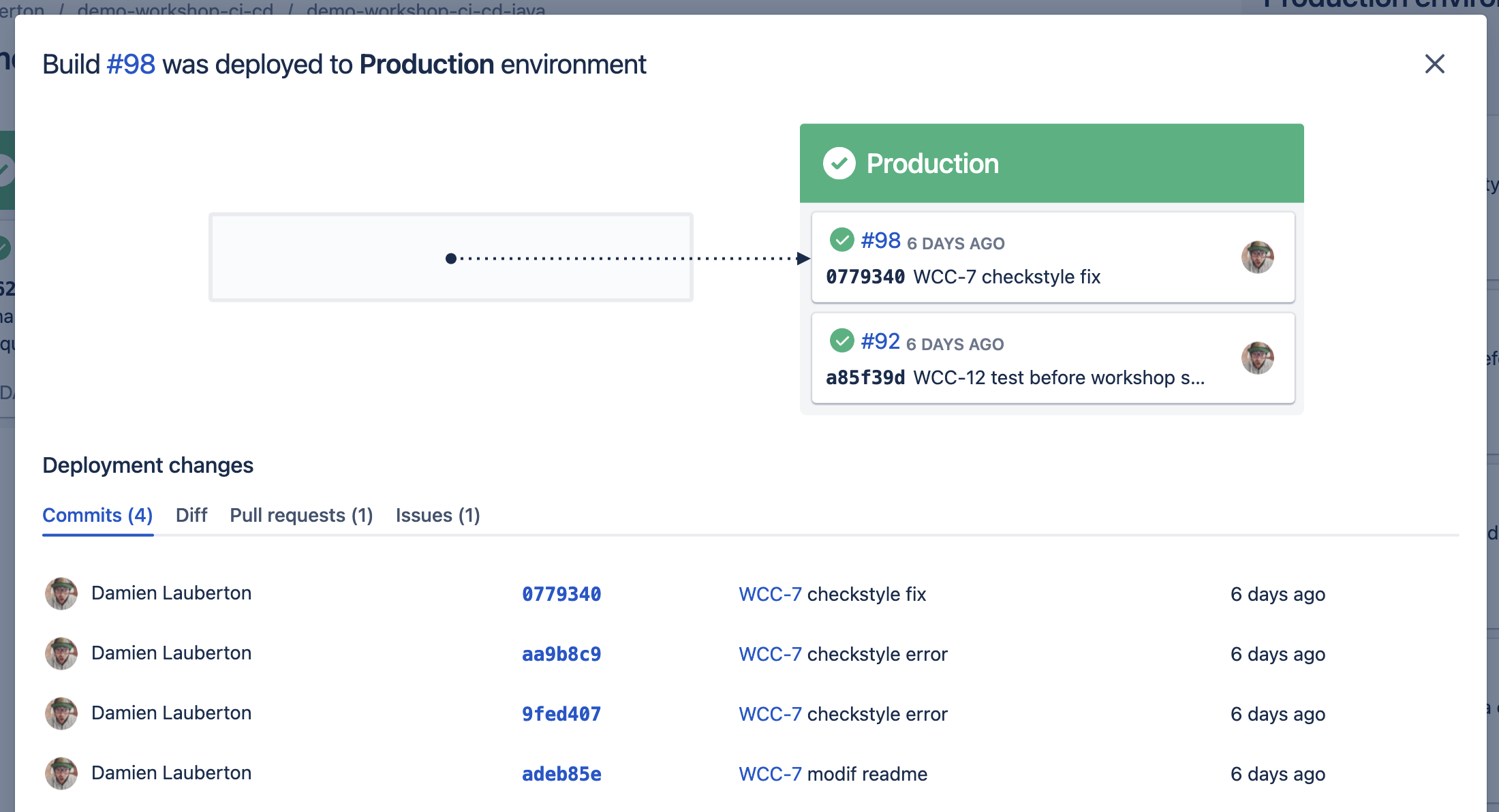
La promotion d’un build
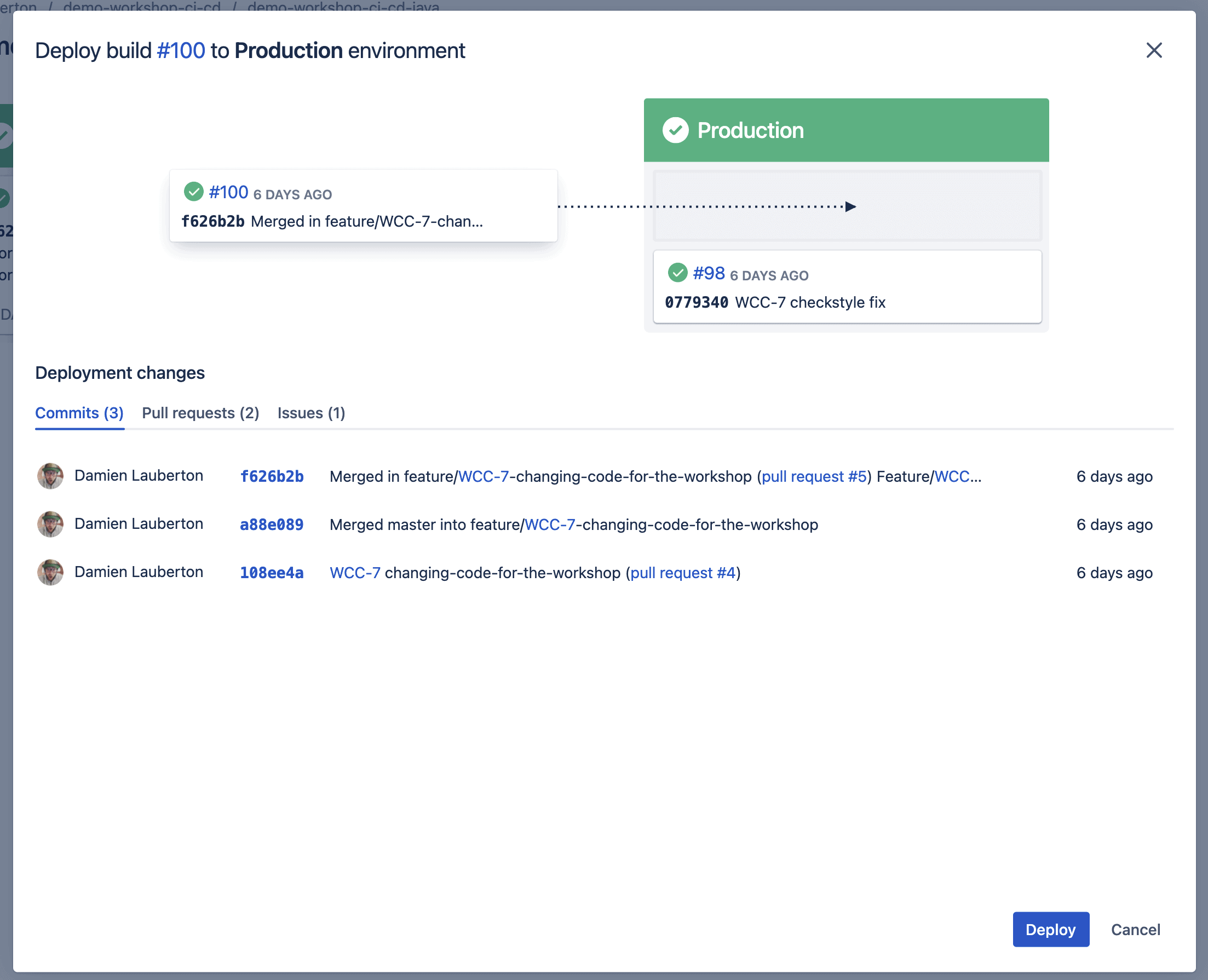
Suite au clic sur « Deploy »
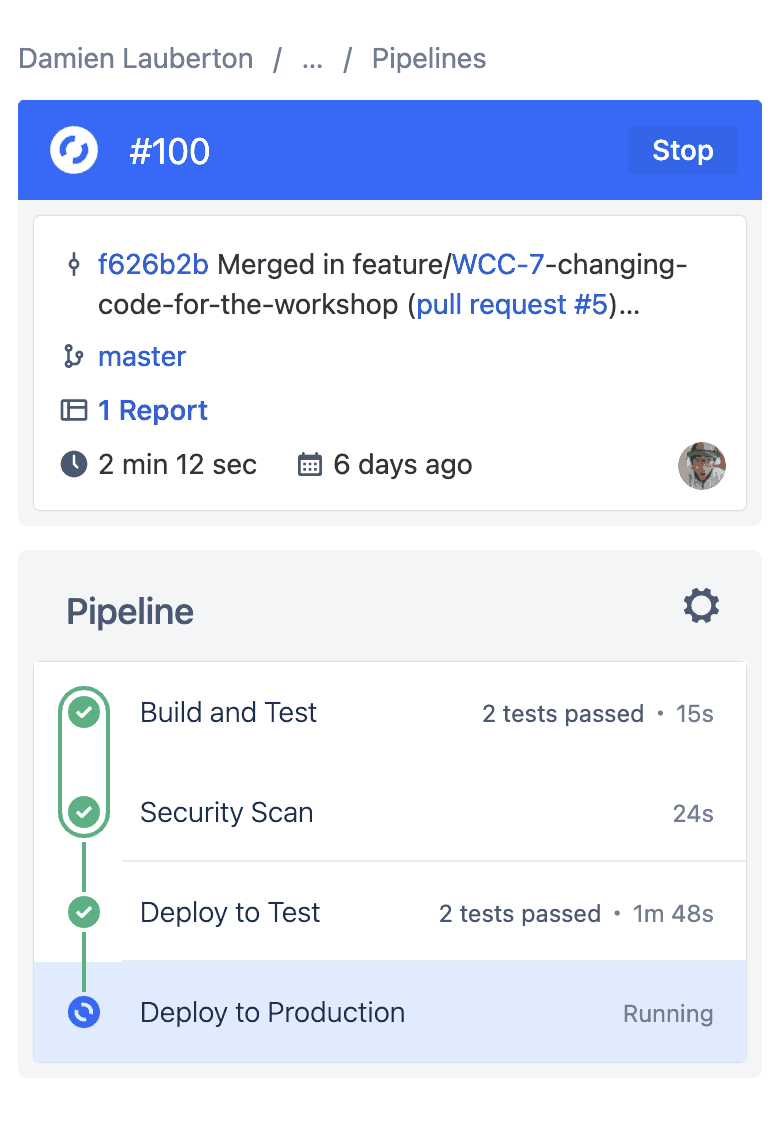
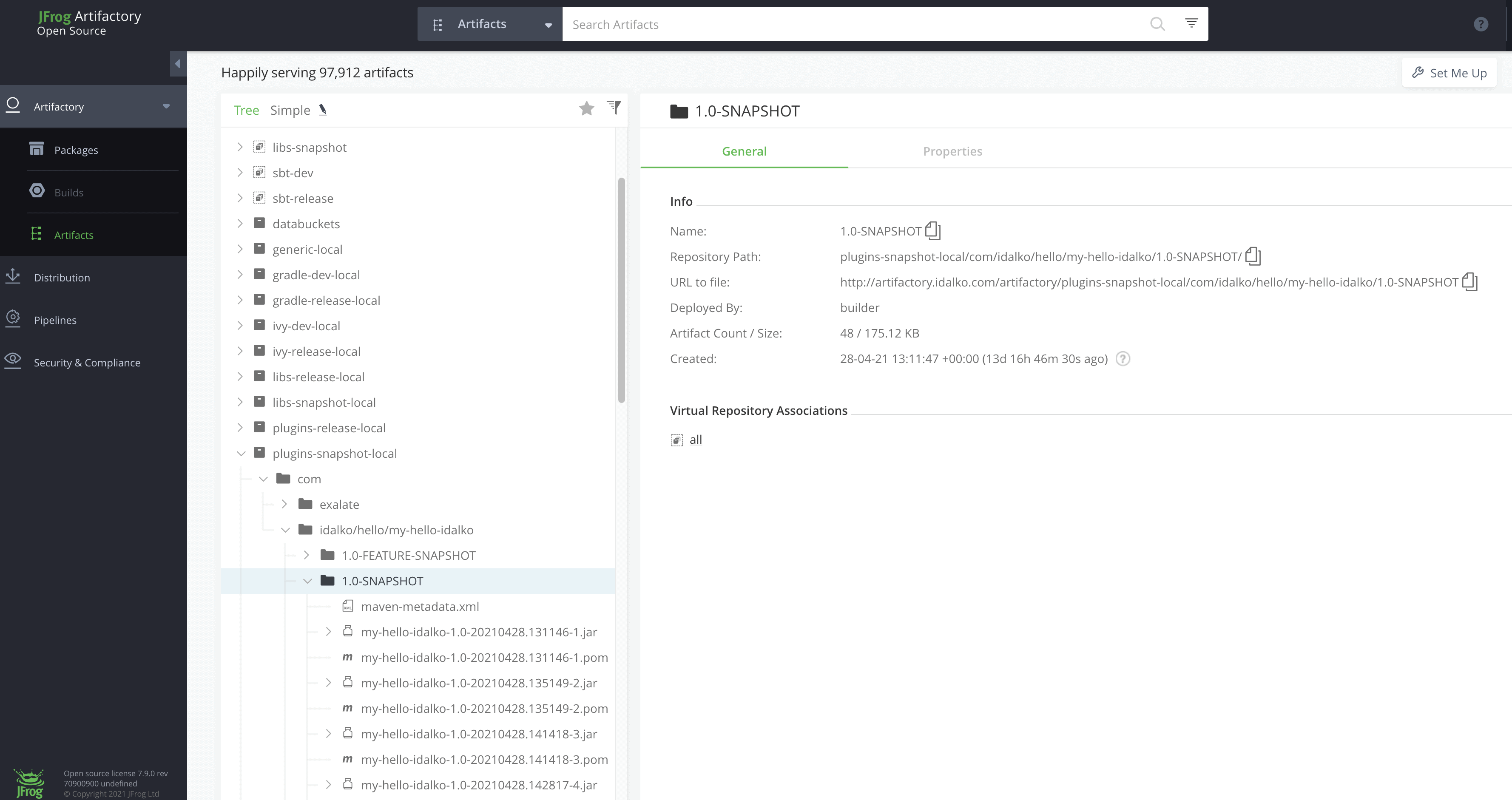
La vue des binaires dans JFrog
Les différentes vues dans Jira Software Cloud
La vue d’un ticket avec le panel « Development »
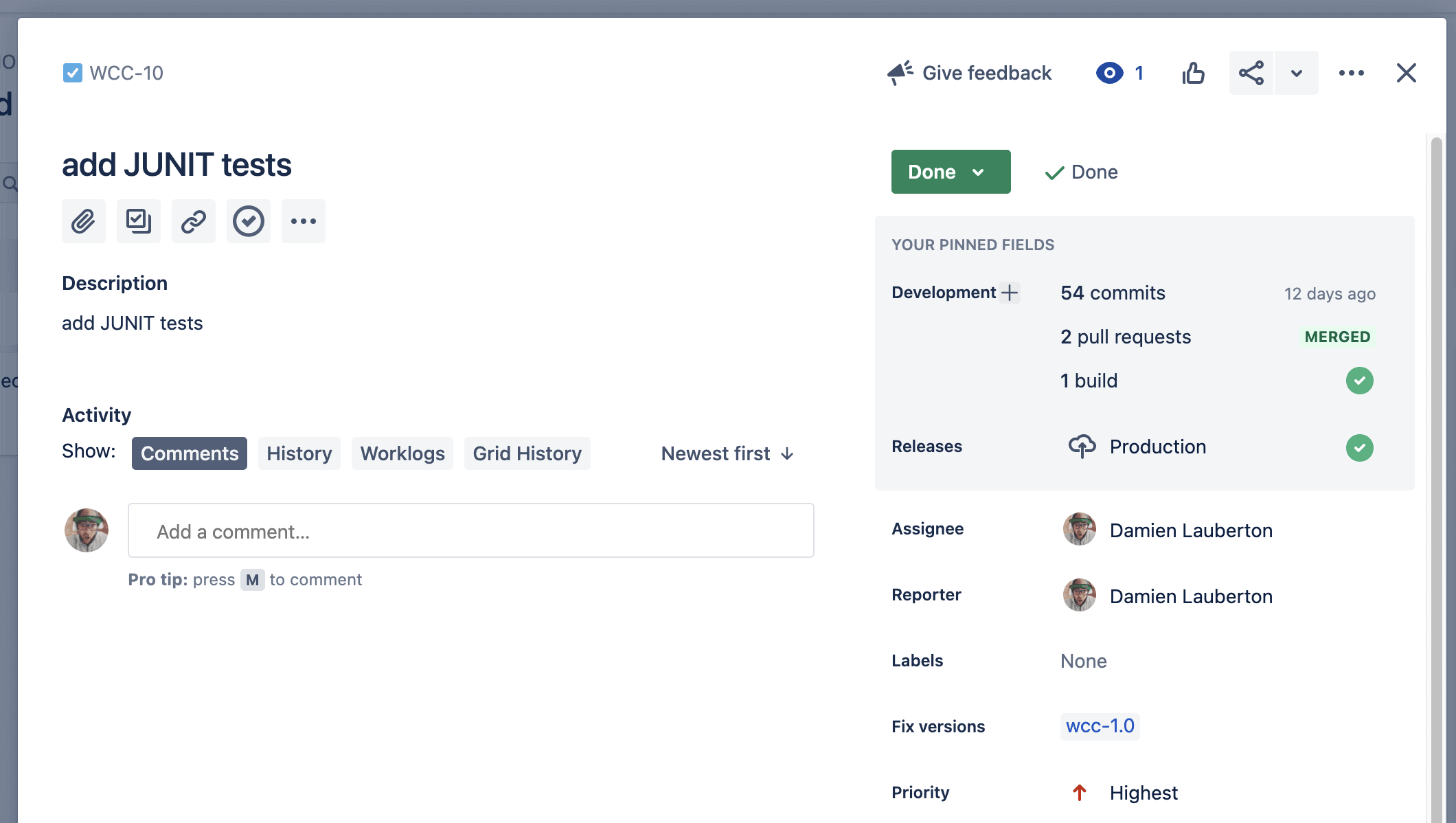
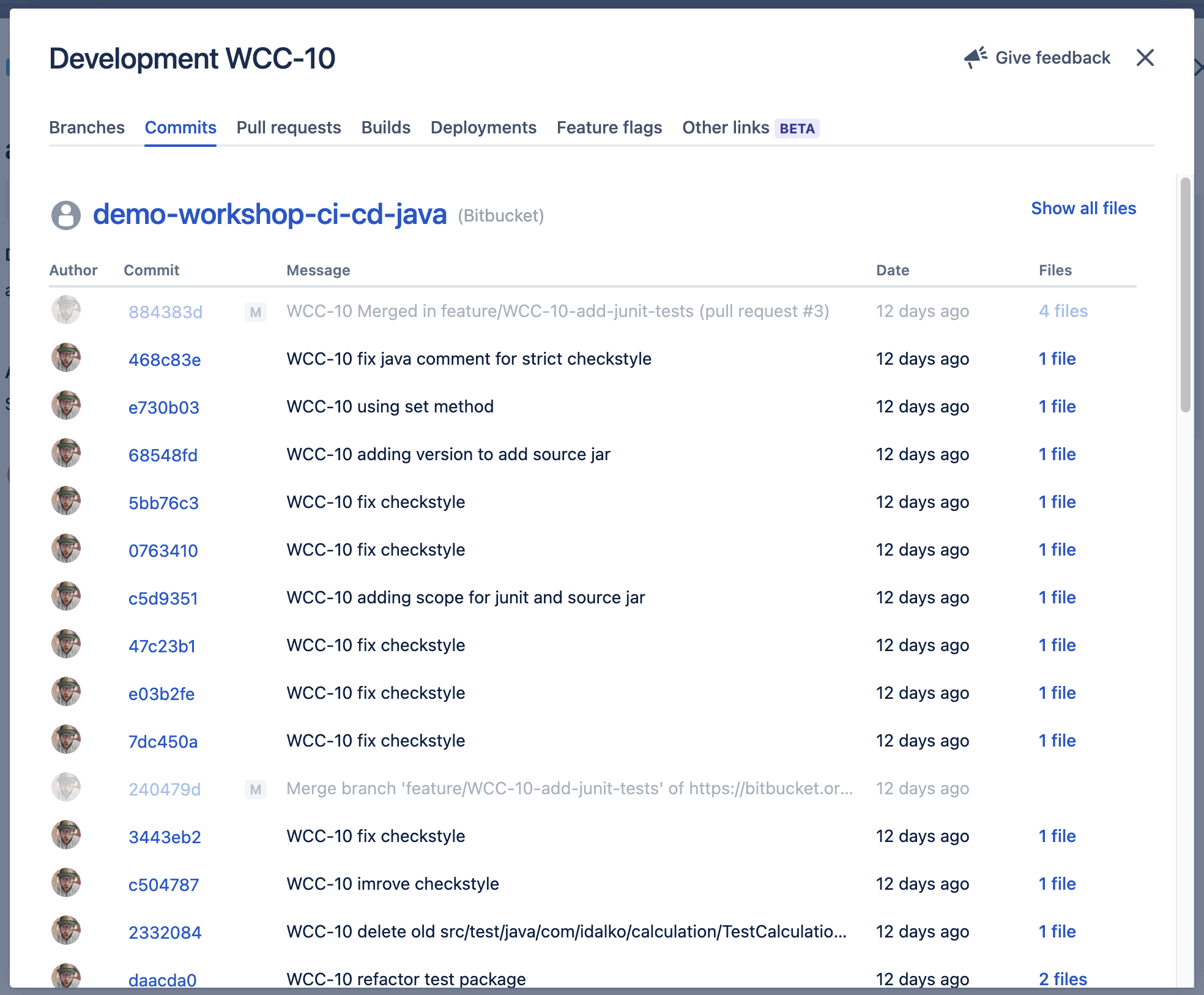
L’historique détaillé des commits
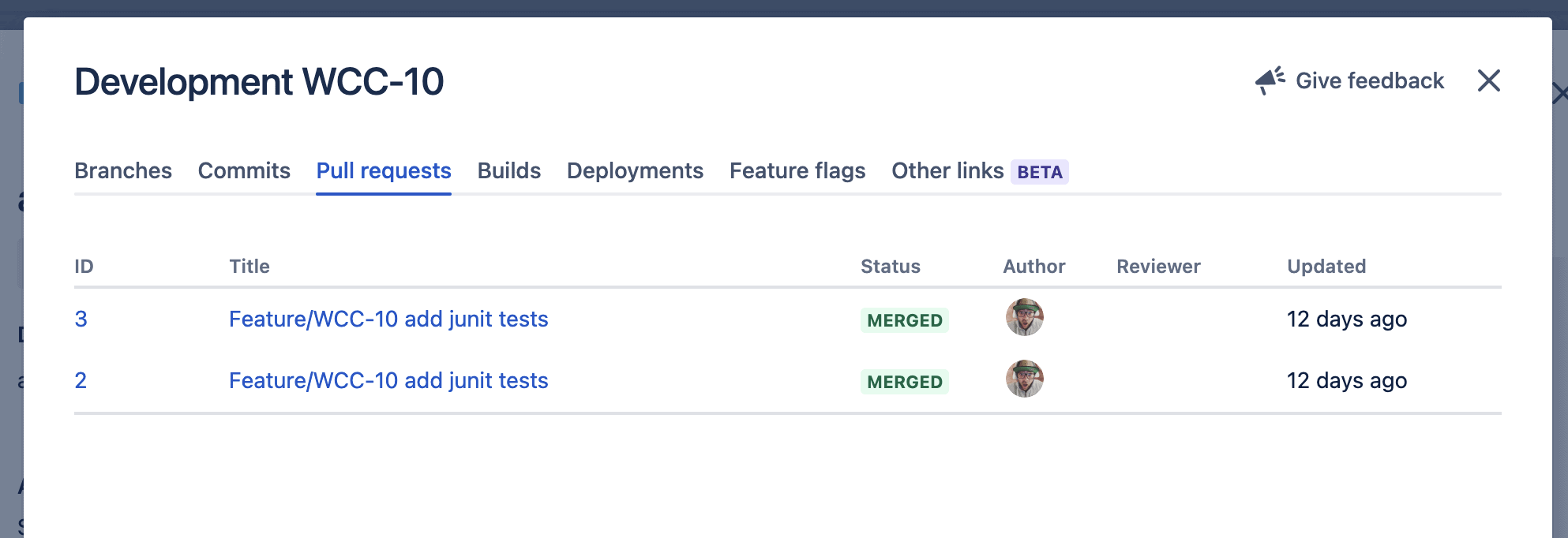
L’historique complet des pull requests
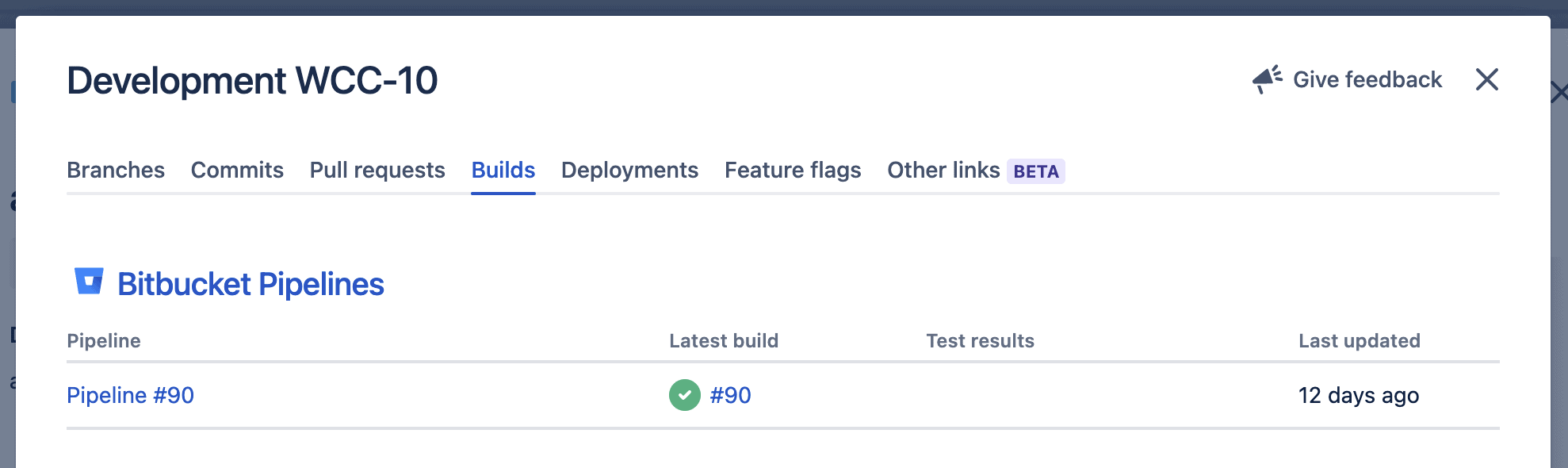
Le dernier build effectué
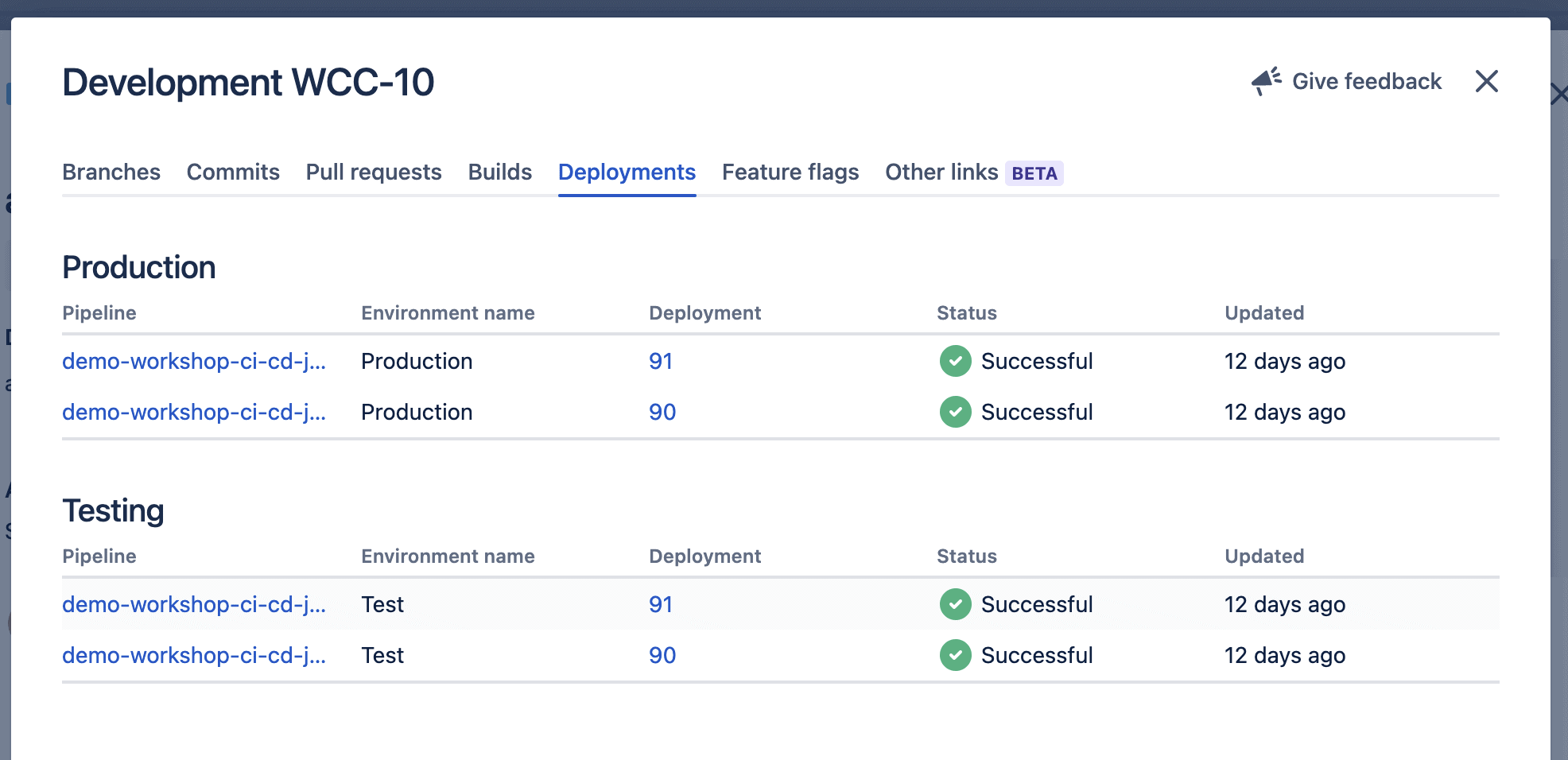
L’historique des déploiements
Cet article a été écrit par Damien Lauberton, un ingénieur Atlassian à iDalko.
Ressources
- PDF de l’atelier en ligne
- Les sources du projet JAVA utilisé pour cette démonstration
- Les ateliers en ligne à venir en Français
- Les ateliers en ligne à venir en Anglais
Remerciements
Merci à iDalko qui sait toujours me dégager du temps pour l’implémentation et la rédaction de ces articles, et un remerciement tout spécial à Atlassian et à leur support tellement rapide et efficace pour m’avoir offert de nombreuses minutes de build sur Bitbucket Pipelines gratuitement.